flowchart LR
X["X(t)"]
Y["X(t+1)"]
E([Encoder])
D([Decoder])
H["h(t)"]
XH["<span style="text-decoration: overline;">X</span>(t+1)"]
L[Reconstruction Loss]
X --> E --> H --> D --> XH
XH --> L
Y ----> L
classDef obs fill:#313244,stroke:#89b4fa,color:#cdd6f4,stroke-width:2px;
classDef net fill:#45475a,stroke:#cba6f7,color:#cdd6f4,stroke-width:2px;
classDef hidden fill:#585b70,stroke:#94e2d5,color:#cdd6f4,stroke-width:2px;
classDef loss fill:#1e1e2e,stroke:#f38ba8,color:#cdd6f4,stroke-width:3px;
class X,Y,XH obs;
class E,D net;
class H hidden;
class L loss;
Introduction
Here’s a number that I’ve been thinking about for a while now. A frontier transformer based LLM today is trained on roughly 10 trillion tokens of text. Ten. A four-year-old child sits in front of you telling stories about their day with grammatical structures that even linguists still don’t fully understand, having ingested roughly the same total amount of raw information through all its biological sensors combined over 16,000 waking hours.
It takes me a moment to accept the scale of this comparison because it forces us to confront something unattractive about modern AI. A growing LLM has processed roughly the same amount of raw information that a four-year-old’s brain has ingested through its entire life. And yet the child can walk across uneven ground, predict where a ball will land, understand that objects keep existing when you look away from them, and tell you why they’re sad about it in sentences most LLMs can’t replicate under real-world constraints.
The numbers are worth pinning down, because the reflex is to assume the child sees vastly more data. It doesn’t. Koch et al. (2006) stuck electrodes into retinal ganglion cells and worked out that the human retina pipes information to the brain at around \(10^7\) bits per second (roughly an Ethernet connection, which I find delightful). Run that for 16,000 waking hours and you get about 70 terabytes through the optic nerve. Throw in audio and the rest of the senses and you land somewhere around 50 to 100 TB over four years. A frontier model trained on ~10 trillion tokens swallows about 40 TB of raw text (call it four bytes a token). Same ballpark. So the budgets are comparable, and whatever edge the child has must come from what its wiring does with them (see the chart below).
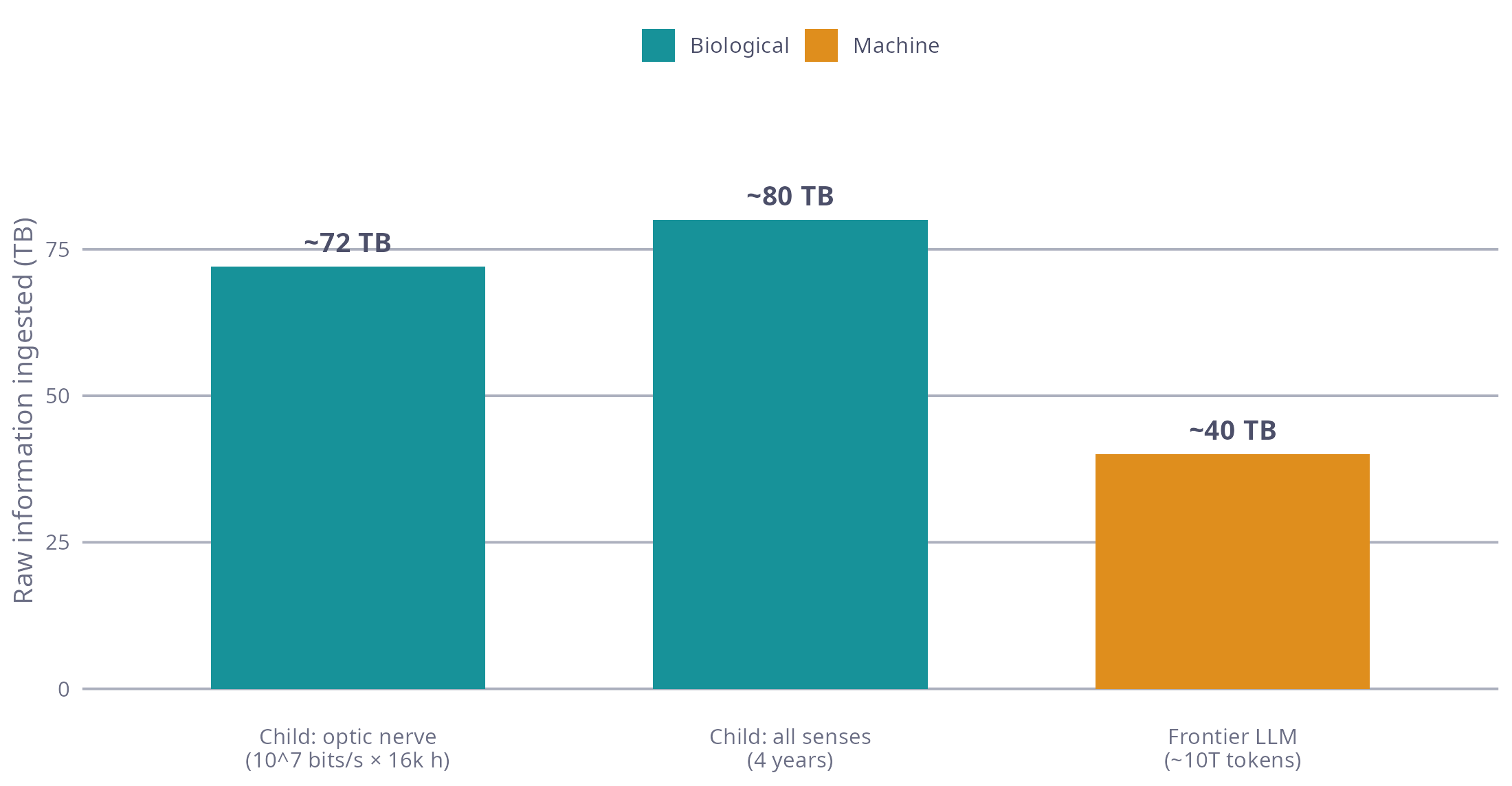
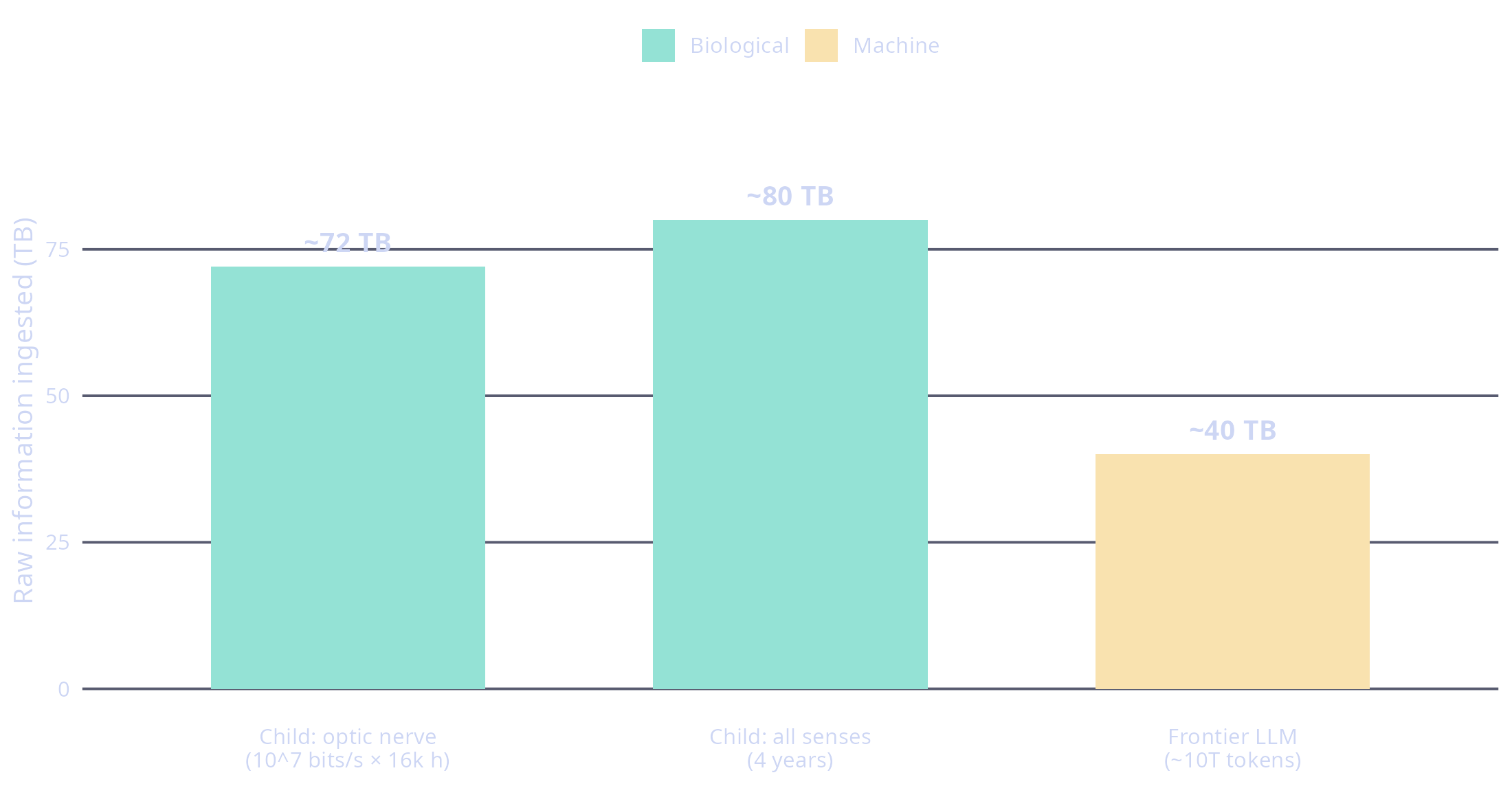
This brings us to a question I have been thinking about for over twenty-five years while working with neural networks.
The data budget is the same for both. What differs is the architecture. A child’s is matched to the problem of learning about reality, while our trillion-token models, for all their sophistication, still cannot pick up a cup without crushing it.
The Data Efficiency Problem We Keep Ignoring
The way today’s approach typically works goes like this. You throw more compute at the problem and hope it scales out. This has worked spectacularly for language models because language is essentially a pattern-matching exercise with enough data to make even statistical coincidences look like meaning. But autonomous agents live in the real world, where there are no shortcuts through text corpora.
In the physical world, causality is messy. Actions have consequences that unfold over time. And most importantly, you get one shot at each interaction. You can’t collect ten trillion training examples of “dropping a glass” before your robot learns to manipulate objects without shattering every dish in the facility. This kind of constraint does not exist for an LLM because tokens are, well, just patterns in text. It’s easy when data is cheap and abundant, but in physics, as I learned early on, the universe never gives you a free pass.
One of the exciting research directions that can pave a new path is World Models, and this is where I think we’ve been going about it wrong for too long. The idea itself is old. Schmidhuber was training recurrent nets to make the world differentiable back in 1990 (Schmidhuber 1990), Ha and Schmidhuber revived it beautifully with the “World Models” paper (Ha and Schmidhuber 2018), and DreamerV2 later showed you really can hit human-level Atari by planning inside a learned latent model (Hafner et al. 2021). But most approaches still try to predict raw observations next-frame or next-token. They’re autoregressive models dressed up in robot clothes, predicting pixels or words one step at a time. This requires massive amounts of data because the model needs to learn both the structure of the world and the compressed representation of what matters simultaneously.
Generative AI fails to construct the forest because they’re so busy learning about the nuance of the color green on a leaf.
What Babies Actually Do
Developmental psychologists have known for decades that human infants don’t do next-pixel prediction. They build internal models. They construct predictions about what will happen next in a latent space. A baby watches a ball roll behind a screen and maintains an expectation of its continued existence, its trajectory. The work of Spelke (1990) on core knowledge and Baillargeon (1987) on violation-of-expectation experiments showed that infants only a few months old already represent objects as bounded, persisting bodies and look longer when a hidden object appears to vanish or pass through a screen. That expectation is stored as a compressed generative model encoded in neural activity that predates language entirely.
The mechanism? Predictive processing theory (Clark 2013) suggests the brain does something remarkably elegant. It maintains hierarchical latent representations at multiple timescales. Higher levels predict what lower levels will see; lower levels send prediction errors up; the system only has to encode surprises.
Now think about what this means for autonomous agents. If we want our robots and embodied systems to learn efficiently, maybe they should do something analogous to what babies do. Build compressed world models. Predict abstract states rather than raw observations. Let the compression do the work of figuring out what matters.
This is essentially what predictive state representations (PSRs) argued decades ago in robotics, but they never got the compute. And now we have it. Still, a good idea without proper training methodology is just philosophy. What actually makes JEPA + SIGReg a good bet today is that someone built the machinery to make it work.
JEPA Gives Us Predictive Latent Spaces
The JEPA family (Joint Embedding Predictive Architecture) grew out of Yann LeCun’s blueprint for autonomous machine intelligence and got its first clean image implementation in I-JEPA (Assran et al. 2023), with a video version following in V-JEPA 2 (Assran et al. 2025). It does something clever. Instead of predicting raw pixels or tokens, it predicts representations in a latent space. And not just any latent space. One built by minimizing the “distance” between predicted and actual embeddings without ever requiring direct access to the raw data during prediction.
To see why this matters, let me put the two architectures next to each other.
First, what we’ve been doing for years. Autoregressive models predict each token or pixel from everything that came before it in observation space. The prediction happens at the level of raw data. Everything flows through a decoder that maps back to pixel/token space, and a loss function compares those predictions against the actual observations. This means the model learns whatever is in your data (signal, noise, artifacts, the whole shabang).
JEPA approaches this in a slightly but significantly different way. You encode observed input segments into latent vectors and a masked Transformer predicts one set of latents from the others, entirely in latent space, with no decoder reconstructing observations. The loss compares predicted embeddings against target embeddings independently coded by a separate network (which gets no gradient). No reconstruction, no pixel-space intermediary.
The architecture works like this.
flowchart LR
X["X(t)"]
Y["X(t+1)"]
CE([Encoder])
TE([Encoder])
ZC["Z(t)"]
ZT["Z(t+1)"]
AT@{ shape: dbl-circ, label: "A(t)" }
P[Predictor]
L[JEPA Loss]
X --> CE --> |Embed| ZC
Y --> TE --> |Embed| ZT
ZC & AT --> P
P --> ZH["<span style="text-decoration: overline;">Z</span>(t+1)"]
ZH --> L
ZT ----> L
classDef obs fill:#313244,stroke:#89b4fa,color:#cdd6f4,stroke-width:2px;
classDef encoder fill:#45475a,stroke:#cba6f7,color:#cdd6f4,stroke-width:2px;
classDef latent fill:#585b70,stroke:#94e2d5,color:#cdd6f4,stroke-width:2px;
classDef predictor fill:#45475a,stroke:#f9e2af,color:#cdd6f4,stroke-width:2px;
classDef loss fill:#1e1e2e,stroke:#f38ba8,color:#cdd6f4,stroke-width:3px;
class X,Y,AT obs;
class CE,TE encoder;
class ZC,ZT,ZH latent;
class P predictor;
class L loss;
The critical thing is that you never reconstruct anything back to pixel or token space. You encode observed segments into latents with f_θ, predict the next latents with a masked transformer φ_θ from those codes plus a context signal driving the predictions, then compare predicted embeddings against target embeddings independently coded by g_θ. The loss operates entirely in embedding space, and if something carries no signal about the task it naturally compresses away.
This is fundamentally different from denoising autoencoders or variational approaches because you’re not trying to reconstruct anything at all. You are building a predictor for abstract states using only the information that was valuable enough to be encoded in the embedding space itself. Which means the model can only learn what it was told to care about, and “told” here comes from the unsupervised structure of the task, not from any hand-crafted objective function. Let the structure do the work, just specify the right inductive biases. I like it!
The sample efficiency comes naturally because JEPA skips whatever portion of raw data carries no information and only predicts what actually changes. A wall moving past your camera? That’s just self-motion, not world dynamics. The latent space can represent “nothing interesting is happening” without having to encode millions of pixels worth of texture.
SIGReg Makes Those Latents Actually Useful
Predicting latents is lovely in theory and has produced nice results in benchmarks, but if your latent representations collapse or become entangled, no amount of clever prediction architecture matters. You need the latents to correspond to something meaningfully structured in the real world for an agent to actually reason over them.
Thus, we need regularisation and that’s precisely where SIGReg comes in, and it’s the piece that makes the whole thing hold together. SIGReg is short for Sketched Isotropic Gaussian Regularization, introduced in the LeJEPA paper by Balestriero and LeCun (2025). The idea is refreshingly clean. They prove that if you want to minimize downstream prediction risk, the embeddings a JEPA should aim for are distributed as an isotropic Gaussian, and SIGReg simply pushes the embeddings toward that distribution. It does the pushing with random projections (the “sketch” in the name), which keeps the whole thing linear in time and memory. That single regularizer replaces the usual pile of heuristics (stop-gradients, teacher-student EMA, learning-rate schedulers) that earlier JEPAs leaned on to avoid collapse.
SIGReg makes JEPA’s predictions actually useful for planning and control rather than just producing smooth embeddings that happen to minimize some loss function. You can’t steer a robot with entangled latents because changing one dimension ripples across every other dimension in unpredictable ways. SIGReg’s regularization prevents exactly this kind of collapse.
The Signal Is in What Both Teach Us Together
JEPA alone gives us efficient prediction, but not necessarily useful structure. SIGReg alone gives us regularized representations, but not an architecture for predicting how the world changes. Together they form a complete learning loop:
- Build latent state representations that are disentangled and stable (SIGReg’s contribution).
- Predict how those latents evolve forward in time (JEPA’s core mechanism).
- Use the predictions to plan actions that produce desired outcomes.
- Observe errors in prediction, send error signals back up the hierarchy, update the model.
This loop is sample-efficient because it operates entirely in latent space and only attends to information that survives both the regularization and the predictive compression. It’s also explainable. Because SIGReg keeps dimensions disentangled, you can trace which dimensions correspond to which physical quantities. You know what changed when something went wrong.
And critically, this architecture mirrors exactly what developmental psychology tells us human brains use to learn about the world. The predictive processing hierarchy, the latent representations at multiple scales, the error-driven updating. Not because babies and JEPA share an evolutionary link (obviously they don’t), but because both are solving the same optimization problem under similar constraints, i.e., limited data, noisy sensors, need for reliable predictions, finite computational capacity.
Why This Is a Good Bet for 2026
A few converging factors make now the right time for this approach in autonomous agents.
First, we finally have compute budgets capable of training meaningful latent world models without immediately collapsing them into useless embeddings. The JEPA papers showed it was possible; we had the architectures but not the discipline to resist next-token distraction long enough to build proper systems.
Second, the robotics community is tired of reinforcement learning’s sample inefficiency and simulation-to-real gap. Every company building autonomous robots knows that collecting real-world data is expensive and dangerous. Architecture-level efficiencies beat brute-force data collection every time.
Third, there’s a growing awareness across ML that scaling laws for autoregressive models might be hitting diminishing returns on the generalization they actually deliver to reasoning and planning tasks. More tokens don’t necessarily translate better to causal understanding or physical manipulation. And we’re starting to see hard numbers on the alternative, e.g., the Semantic Tube Prediction work (Huang et al. 2026) applied a JEPA-style regularizer to a language task and matched baseline accuracy with 16 times less training data, which is a direct poke at the data term of the Chinchilla scaling laws.
JEPA + SIGReg addresses all three of these concerns head-on by providing an architecture-level solution that can learn efficiently from less data because you’re predicting the right things, at the right level of abstraction, with representations you can trust enough to act on.
Where I’m Uncertain
I want to be transparent about what’s not yet proven here. The JEPA + SIGReg literature so far has been mostly shown in controlled environments like Atari games (Hafner et al. 2021) and synthetic dynamics tasks. LeWorldModel (Maes et al. 2026) is encouraging on this front, since it trains a stable JEPA end-to-end from raw pixels on a single GPU and its latent space actually probes out to physical quantities, but that’s still a long way from open-world robotics with its dense sensors, actuator noise, and unstructured interactions. Whether the approach scales there remains an open question.
There’s also the question of language grounding. LLMs at least have some connection to structured human knowledge because they’re trained on it. A JEPA-based agent that learns purely from sensorimotor experience might develop a perfectly competent world model that has no interface for communicating what it learned. This is solvable, I think (VL-JEPA (Chen, Shukor, et al. 2025) and the Vision Language World Model (Chen, Moutakanni, et al. 2025) are early attempts to bolt a language interface onto exactly this kind of predictive latent space), but it’s a different problem from the one autoregressive models solve naturally.
Finally, I haven’t fully worked out how regularizing latent spaces interacts with safety guarantees. If we’re teaching agents to act on their compressed predictions, the gap between prediction and reality becomes a critical design question. SIGReg helps by keeping latents stable and interpretable, but that’s not the same as bounding error in downstream planning.
Write to me if you’ve worked at this intersection and what you see differently. I’m always trying to calibrate my optimism on new architectures against real-world deployment data, which is still thin for anything like the approach we need here.
Conclusion
Language models are genuinely remarkable at what they do, and they serve a different purpose than the one I’m describing here. I’m running the comparison between token counts and infant sensory bandwidth to sharpen a point about architecture. For autonomous agents that need to learn quickly from limited experience in the physical world, we should be studying what works under the same constraints as biological learners, meaning compressed representations, predictive internal models, hierarchical error correction.
JEPA provides the predictive architecture. SIGReg ensures the latents remain usable. Together they offer something I haven’t seen enough of in recent AI literature. An approach to agent learning that is principled about data efficiency, grounded in what we know about biological development, and actually buildable with current tools.
The bet is that this combination will prove more effective at scale for teaching agents the kind of general reasoning you get from early childhood observation than the brute-force token accumulation strategy has shown itself to be. I’ve been working in neural network research long enough to know that architecture-level advantages compound over pure data volume, so this seems like an asymmetrically good bet. Significant upside if it works, manageable cost either way because even partial gains in sample efficiency for robot and agent learning could be commercially transformative.
But the real reason to build agents this way is that I find it deeply satisfying on its own terms. Systems that learn efficiently from compressed observation, without needing encyclopedic data ingestion, reflect something true about intelligence rather than just scaling brute force. That’s worth building toward on principle, regardless of whether it scales commercially.
And honestly? If a four-year-old can figure out how the world works with the sensors it got through the optic nerve, surely our models could learn to do at least as well, even if they need more computation than their tiny human counterparts.
References
Assran, Mahmoud, Quentin Duval, Ishan Misra, et al. 2023. “Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture.” 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Vancouver, BC, Canada), June, 15619–29. https://doi.org/10.1109/CVPR52729.2023.01499.
Assran, Mido, Adrien Bardes, David Fan, et al. 2025. V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning. arXiv:2506.09985. arXiv. https://doi.org/10.48550/arXiv.2506.09985.
Baillargeon, Renée. 1987. “Object Permanence in 3.5- and 4.5-Month-Old Infants.” Developmental Psychology 23 (5): 655–64. https://doi.org/10.1037/0012-1649.23.5.655.
Balestriero, Randall, and Yann LeCun. 2025. LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics. arXiv:2511.08544. arXiv. https://doi.org/10.48550/arXiv.2511.08544.
Chen, Delong, Theo Moutakanni, Willy Chung, et al. 2025. Planning with Reasoning Using Vision Language World Model. arXiv:2509.02722. arXiv. https://doi.org/10.48550/arXiv.2509.02722.
Chen, Delong, Mustafa Shukor, Theo Moutakanni, et al. 2025. VL-JEPA: Joint Embedding Predictive Architecture for Vision-language. arXiv:2512.10942. arXiv. https://doi.org/10.48550/arXiv.2512.10942.
Clark, Andy. 2013. “Whatever Next? Predictive Brains, Situated Agents, and the Future of Cognitive Science.” Behavioral and Brain Sciences 36 (3): 181–204. https://doi.org/10.1017/S0140525X12000477.
Ha, David, and Jürgen Schmidhuber. 2018. “World Models.” March 28. https://doi.org/10.5281/zenodo.1207631.
Hafner, Danijar, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. 2021. “Mastering Atari with Discrete World Models.” International Conference on Learning Representations (ICLR). https://doi.org/10.48550/arXiv.2010.02193.
Huang, Hai, Yann LeCun, and Randall Balestriero. 2026. Semantic Tube Prediction: Beating LLM Data Efficiency with JEPA. arXiv:2602.22617. arXiv. https://doi.org/10.48550/arXiv.2602.22617.
Koch, Kristin, Judith McLean, Ronen Segev, et al. 2006. “How Much the Eye Tells the Brain.” Current Biology 16 (14): 1428–34. https://doi.org/10.1016/j.cub.2006.05.056.
Maes, Lucas, Quentin Le Lidec, Damien Scieur, et al. 2026. LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels. arXiv:2603.19312. arXiv. https://doi.org/10.48550/arXiv.2603.19312.
Schmidhuber, Jürgen. 1990. Making the World Differentiable: On Using Self-Supervised Fully Recurrent Neural Networks for Dynamic Reinforcement Learning and Planning in Non-Stationary Environments. FKI-126-90. TUM.
Spelke, Elizabeth S. 1990. “Principles of Object Perception.” Cognitive Science 14 (1): 29–56. https://doi.org/10.1207/s15516709cog1401_3.