Introduction
OK, controversial statement incoming (and probably unpopular). Most marketing measurement is still built on the assumption that if you can track a click, you can explain an outcome.
That assumption died. Not due in a dramatic privacy regulation announcement, as you would think even though that of course played a role. IMHO it died quietly, over years, as cookie windows shrank, attribution models crumbled, and the gap between what dashboards show and what actually happens grew.
So what replaces it? That is a question a lot of marketing leaders should be asking right now. Some have answers (usually ones that sell something). I have one too, and mine happens to involve Bayesian statistics and a fair bit of physics intuition.
I know mentioning physics can seem a bit mathy and heavy but the point in this post is the thinking, not the formulas.
The Attribution Problem Nobody Fixes
Let me start with something concrete. Traditional attribution takes user journeys and assigns credit to touchpoints. Click a Facebook ad, view a search result, land on the site, convert. The attribution model (first-touch, last-touch, data-driven, Markov chains) splits the credit between those steps.
This is fine, in theory. The problem is the theory assumes you can observe all relevant touchpoints. You can’t. People see ads offline. They talk to friends. They remember a podcast from three weeks ago. None of that appears in the clickstream.
Worse, attribution models reward visibility, not causality. The channel that gets the most credit is often the one closest to the purchase moment or the one with the best tracking pixel, not the one that actually generated demand. I’ve seen this firsthand. The channel that gets the most credit is rarely the channel doing the heavy lifting. This is not a hunch: when Gordon et al. (2019) ran large field experiments at Facebook and compared the experimental ground truth against common attribution methods, the attribution numbers were off, sometimes by enough to flip the decision.
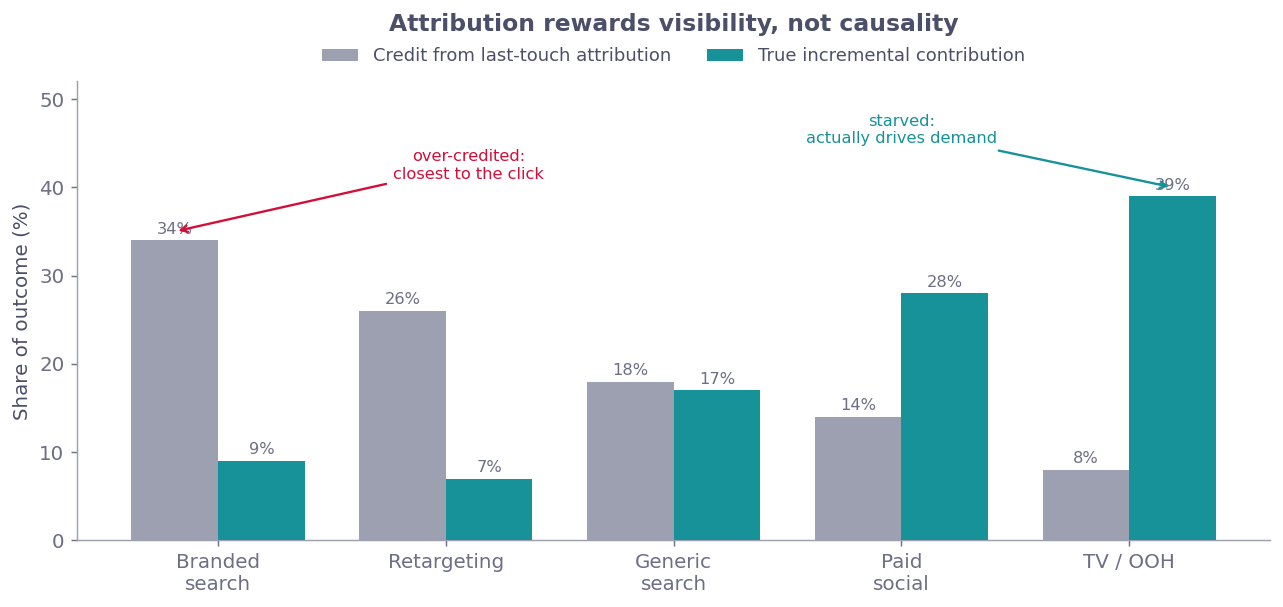
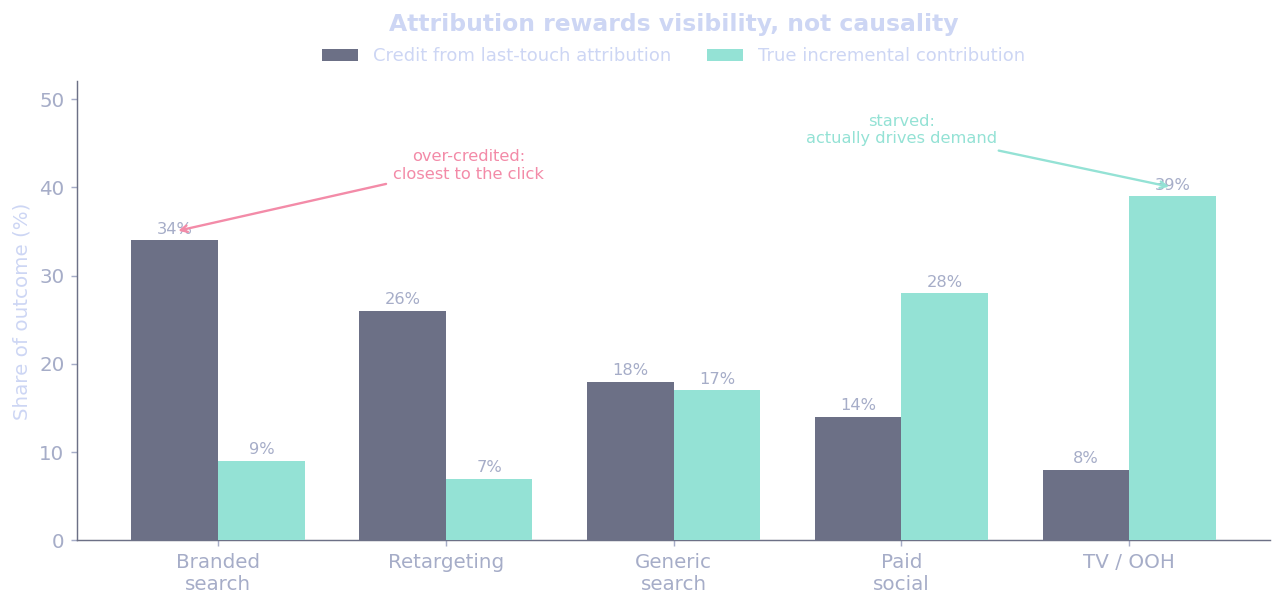
But why does this matter to us when building marketing systems? Because if you’re optimizing based on biased credit assignment, you’re not optimizing. You’re just playing Whac-A-Mole with your budget.
Incrementality is “The Real Question”
So what should we optimize for? Incrementality. The question is not “did they click?” The question is “would they have bought anyway?”
This is a causal question. Not statistical. Not correlational. Causal. And causal questions need either experiments (where you control what happens) or models that properly separate signal from the background noise.
Both approaches have a Bayesian core.
Experimental design (geo lift tests, holdout groups) tells you what works, but running them is expensive and slow. You’re splitting your market, holding back spend, and waiting weeks for results. Meanwhile your competitors aren’t waiting.
Models (marketing mix models at their best) tell you what’s happening right now, across all channels simultaneously, but they need honest priors and honest data. And honest data is hard to find when every dashboard is configured to make someone look good.
The Bayesian Advantage Nobody Talks About
In physics, when you measure something, you never get one clean number. You get an observation plus uncertainty. The uncertainty is not noise. The uncertainty is information.
Bayesian methods treat uncertainty as first-class (Gelman et al. 2013). Every parameter in a marketing mix model carries a posterior distribution, not a point estimate. That means when you ask “what’s the return on TV spend?” you don’t get “$4.20”. You get “$4.20, but it’s probably between $3.10 and $5.60 with 95% confidence, and here’s how confident we are in those bounds given the data you actually have.”
This is not a detail. This is the whole point.
When marketing leaders see a single number for campaign performance, they make decisions. Those decisions are often wrong because the uncertainty around that number matters more than the number itself. The point estimate is the least interesting thing about the result.
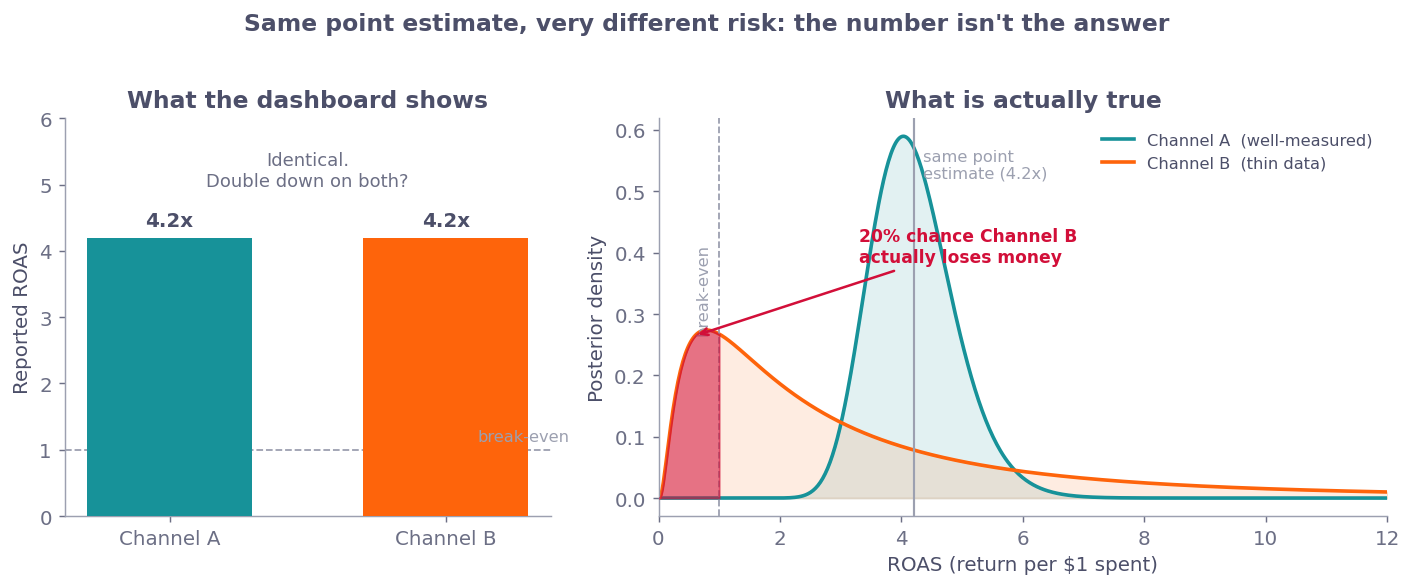
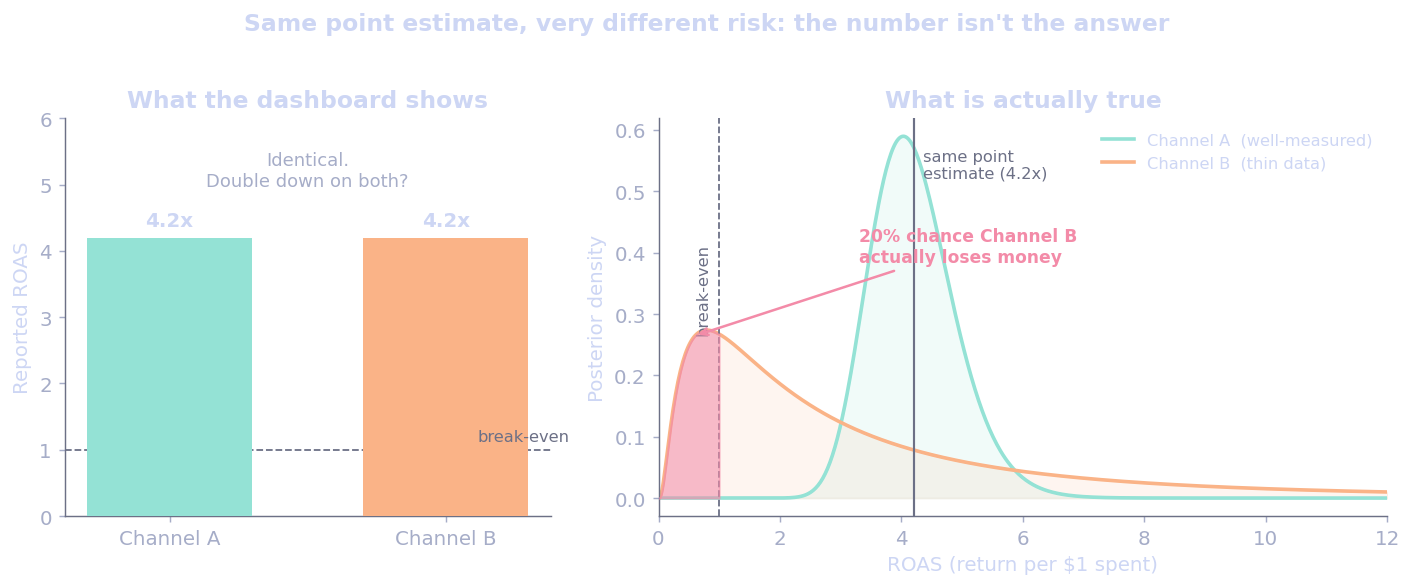
Marketing Mix Modeling Gets a Bad Reputation (Unfairly)
I know, I know. MMM has baggage. Everyone has a story where the model said spend more on OOH and growth flatlined.
Well, that’s total BS when it comes to the method itself. It’s great when executed properly with Bayesian foundations, honest data, and the humility to update the model when reality disagrees. It’s bad when you plug it into a dashboard, trust the outputs blindly, and never question the assumptions.
The old school MMM is coming back, because the alternatives broke. The privacy landscape forced the hand. Apple’s ATT, cookie deprecation, Google’s timeline delays then reversals, the GDPR reality on the ground. The tracking infrastructure that attribution depended on is crumbling, and the companies that built businesses on top of it are finally saying “maybe we need something else.”
The revival is real. The question is whether the new MMM will learn from the old mistakes or just repeat them with shinier priors. The good versions already exist in the literature: Jin et al. (2017) lay out a Bayesian MMM that handles carryover (adstock) and shape (saturation) effects properly, which is exactly the kind of structure the dashboard-era models skipped.
What I Actually Do About It
OK, I’ve complained enough. What do I actually do?
I run Alviss AI. We provide decision infrastructure for marketing teams. Not dashboards, not reporting widgets, but systems that help companies separate what they want to believe from what’s actually happening. The product sits at the intersection of marketing science and proper measurement frameworks. The goal is to give marketing leaders models that carry their own uncertainty forward into the recommendations, so when the system says “shift budget from channel A to channel B,” it also tells you how confident it is in that shift and what could break the conclusion.
I’ll be the first to admit there’s still a lot more to understand in this space. The marketing measurement landscape is evolving fast, and the Bayesian tools need to keep up with the data problems, not the other way around.
A Physics Lesson for Marketing
Right, one more thought before I wrap this up.
In theoretical physics, we have this concept called a Hamiltonian. It’s a function that describes the total energy of a system. You write it down, you solve the equations of motion, and the system evolves. If your Hamiltonian is wrong, the whole simulation is wrong. No amount of compute fixes a wrong Hamiltonian.
Marketing mix modeling has the same problem. Your model structure is your Hamiltonian. If you get the structure wrong (wrong functional form for ad response, ignored saturation effects, no carry-over), the outputs are fiction, no matter how much data you pour in.
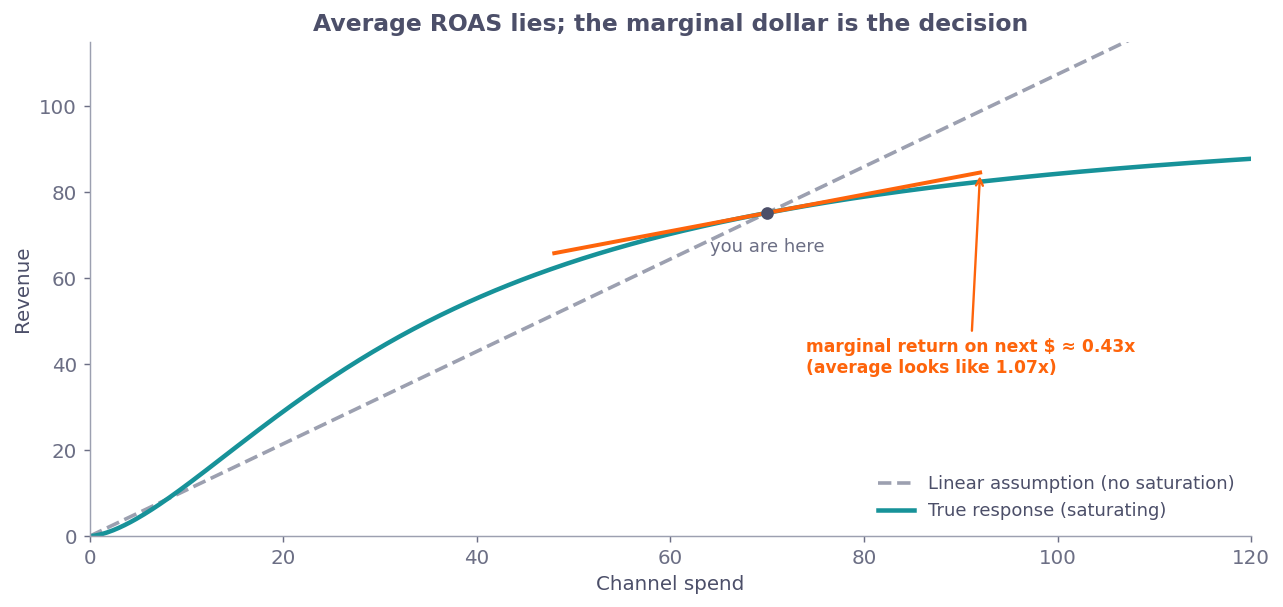
The good news? There are principled ways to build the structure. Saturation curves from physics (Michaelis-Menten kinetics, if you want the nerdy reference) map perfectly to ad response curves. Bayesian hierarchical models let you borrow strength across channels while respecting their differences. The math exists. It’s been around. Nobody is inventing anything new.
We just need to use the right tools and stop pretending that click data is a proxy for truth.
Conclusion
Marketing science is not a sexy topic. It doesn’t generate keynotes or conference applause. But it is the backbone of how companies decide where money goes, which products get exposure, and whether growth is real or inflated by measurement artefacts.
The companies that get ahead are not the ones with the best dashboards. They’re the ones with the most honest measurement frameworks and the right infrastructure to make better decisions. That means Bayesian uncertainty, proper causal thinking, and the humility to admit when a model disagrees with reality.
The tools for better marketing measurement are already here. It’s time we used them properly.